Nakamoto ResearchThe Bitcoin whitepaper |
Version | v0.3.4 | |
|---|---|---|---|
| Updated | |||
| Author | obxium | License | BY-NC-ND |
Satoshi Nakamoto announced release of the Bitcoin whitepaper, titled “Bitcoin: A Peer-to-Peer Electronic Cash System,” in different communications channels on October 31, 2008.
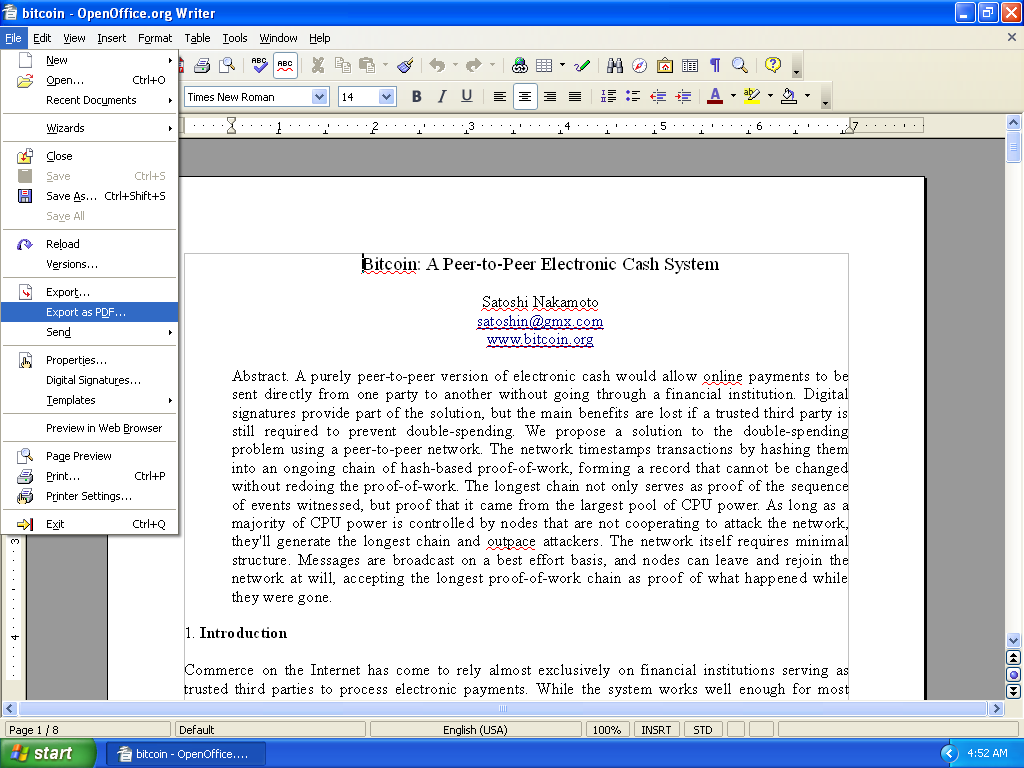
ARTISTIC REENACTMENT What it could have been like that day as Nakamoto exported the whitepaper PDF.
Friday Oct 31 14:10:00 EDT 2008, Nakamoto used the
satoshi@vistomail.com email address to announce the paper
in a popular mailing list for cypherpunks, in a post entitled Bitcoin
P2P e-cash paper:
I've been working on a new electronic cash system that's fully
peer-to-peer, with no trusted third party.
The paper is available at:
http://www.bitcoin.org/bitcoin.pdf
The main properties:
Double-spending is prevented with a peer-to-peer network.
No mint or other trusted parties.
Participants can be anonymous.
New coins are made from Hashcash style proof-of-work.
The proof-of-work for new coin generation also powers the
network to prevent double-spending.
Bitcoin: A Peer-to-Peer Electronic Cash System
Abstract. A purely peer-to-peer version of electronic cash would
allow online payments to be sent directly from one party to another
without the burdens of going through a financial institution.
Digital signatures provide part of the solution, but the main
benefits are lost if a trusted party is still required to prevent
double-spending. We propose a solution to the double-spending
problem using a peer-to-peer network. The network timestamps
transactions by hashing them into an ongoing chain of hash-based
proof-of-work, forming a record that cannot be changed without
redoing the proof-of-work. The longest chain not only serves as
proof of the sequence of events witnessed, but proof that it came
from the largest pool of CPU power. As long as honest nodes control
the most CPU power on the network, they can generate the longest
chain and outpace any attackers. The network itself requires
minimal structure. Messages are broadcasted on a best effort basis,
and nodes can leave and rejoin the network at will, accepting the
longest proof-of-work chain as proof of what happened while they
were gone.
Full paper at:
http://www.bitcoin.org/bitcoin.pdf
Satoshi NakamotoHere are some key aspects of the original whitepaper:
Nakamoto introduced Bitcoin as an academic paper, and the Bitcoin papers cites other academic papers. It stands to reason that one or more of the involved actors had or has academic ties, and has likely published similar papers before.
Academic computer scientists have a particular penchant for formatting their papers with TeX or LaTeX.
It’s entirely possible that Nakamoto didn’t author the whitepaper in OpenOffice Writer, but instead wrote the paper in TeX (or LaTeX), imported that file into OpenOffice, and exported the PDF from OpenOffice Writer as a measure of misdirection.
These are notes on research into the original Bitcoin whitepaper PDF file.
The file used in these notes is from https://bitcoin.org/bitcoin.pdf.
Satoshi Nakamoto released the original Bitcoin whitepaper as a PDF document. I’ve used open source tools and techniques to analyze the facts and structure in this document.
Use the SHA-256 hash summary value to check the file integrity:
SHA-256 summary for bitcoin.pdf:
b1674191a88ec5cdd733e4240a81803105dc412d6c6708d53ab94fc248f4f553PDF structure analysis:
pdfid.py bitcoin.pdf
PDFiD 0.2.8 bitcoin.pdf
PDF Header: %PDF-1.4
obj 67
endobj 67
stream 23
endstream 23
xref 1
trailer 1
startxref 1
/Page 9
/Encrypt 0
/ObjStm 0
/JS 0
/JavaScript 0
/AA 0
/OpenAction 1
/AcroForm 0
/JBIG2Decode 0
/RichMedia 0
/Launch 0
/EmbeddedFile 0
/XFA 0
/URI 0
/Colors > 2^24 0This version of the whitepaper shows 1 /OpenAction. An
open action is any action, such as a request to an external website,
that triggers when you open the file.
Examine the document for stream objects to find that the
/OpenAction is object 66:
pdf-parser.py -a -O bitcoin.pdf
Comment: 3
XREF: 1
Trailer: 1
StartXref: 1
Indirect object: 67
42: 2, 3, 5, 6, 8, 9, 11, 12, 14, 15, 17, 18, 20, 21, 23, 24, 26, 27, 29, 30, 32, 34, 35, 37, 39, 40, 42, 44, 45, 47, 49, 50, 52, 54, 55, 57, 59, 60, 62, 64, 65, 67
/Catalog 1: 66
/Font 7: 33, 38, 43, 48, 53, 58, 63
/FontDescriptor 7: 31, 36, 41, 46, 51, 56, 61
/Page 9: 1, 4, 7, 10, 13, 16, 19, 22, 25
/Pages 1: 28
Search keywords:
/OpenAction 1: 66Examine stream object 66:
pdf-parser.py -o 66 bitcoin.pdf
obj 66 0
Type: /Catalog
Referencing: 28 0 R, 1 0 R
<<
/Type /Catalog
/Pages 28 0 R
/OpenAction [1 0 R /XYZ null null 0]
/Lang (en-GB)
>>This is an explicit destination stream object included in all OpenOffice documents to present the first page of the document with desired settings.
There’s nothing to worry about here, although the reference to the en-GB language for the document is certainly interesting. Whether it’s a genuine reflection of the operating environment at time of document authoring or a clever ruse is unknown.
When researching at the metadata level, some critical document properties emerge, namely details about the document creation. These details include the software and version along with creation date.
This page presents some of those details in plain text followed by their actual representation in the document, which sometimes includes hexadecimal encoding.
You can view and navigate through the entire document properties with:
pdfparser.py bitcoin.pdf | lessIf you browse the PDF data, the first thing you’ll note are 2 PDF comments. The first is just the PDF version:
PDF Comment '%PDF-1.4\n'Then there’s another PDF comment as a hex dump value:
PDF Comment '%\xc3\xa4\xc3\xbc\xc3\xb6\xc3\x9f\n'This comment decodes to the UTF-8 characters plus a new line:
äüößIt’s unclear what this selection of German umlaut characters means, if anything.
A final comment value occurs at the end of the document:
PDF Comment '%%EOF\n'The PDF comment appears just to be an EOF and end of line character:
'%%EOF\n', or effectively an empty comment value.
The /CreationDate in the file is
D:20090324113315-06'00'.
This appears to be a Unix timestamp with timezone offset.
Here’s how it breaks down:
D: indicates the timestamp is in a Unix-like
format.2009 is the year (2 digits, representing 20XX).0324 represents March twenty-fourth (03 = March, 24 =
day of the month).11:33:15 specifies the time (11 hours, 33 minutes, and
15 seconds).The timezone offset -06'00' indicates an offset
from UTC.
In this case:
-06 represents a timezone offset of -6 hours from
Coordinated Universal Time (UTC).'00' indicates no daylight saving time (DST).Interpreted correctly, this would equate to:
2009-03-24 11:33:15 UTC-06
The original value is hex-encoded:
<FEFF005700720069007400650072>and decodes to the English word Writer.
It’s not clear what ‘Writer’ means here, but the initial hunch is that it refers to OpenOffice Writer, a component of the OpenOffice suite. This suggests that tool is part of the authoring workflow. Of course, it could also just be a ruse to disguise the true authoring workflow.
More research into what can appear in this field by default from the software in question will help to push the topic further
The original value is hex-encoded:
<FEFF004F00700065006E004F00660066006900630065002E006F0072006700200032002E0034>and decodes to OpenOffice 2.4.
The document checksum represented in the PDF is:
6F72EA7514DFAD23FABCC7A550021AF7.
The /ID field is interesting, because it’s an MD5 digest
of concatenated key document metadata items covered earlier with some
known and some unknown values:
unknownunknownunknownWriterOpenOffice 2.4D:20090324113315-06'00' or
2009-03-24 11:33:15 UTC-06 (or other variation)/ID [<CA1B0A44BD542453BEF918FFCD46DC04><CA1B0A44BD542453BEF918FFCD46DC04>]The advanced PDF forensics page details this further, including the source code responsible for generating this value.
You can also use exiftool to process the file.
These are relevant details from the output of
exiftool bitcoin.pdf. They’re pretty much the same results
that pdfid.py outputs, but the exiftool has
cleaner output:
File Size : 184 kB
File Type : PDF
File Type Extension : pdf
MIME Type : application/pdf
PDF Version : 1.4
Linearized : No
Page Count : 9
Language : en-GB
Creator : Writer
Producer : OpenOffice.org 2.4
Create Date : 2009:03:24 11:33:15-06:00You can also use code, like this Python example to fetch the PDF from
its URL and process it directly. The output will also be like that
produced by exiftool or pdfid.py.
pip3 install --quiet --quiet --user pdfplumber && \
cat > /tmp/bitcoin_paper.py << EOF
import io
import json
import pdfplumber
import requests
url = "https://bitcoin.org/bitcoin.pdf"
content = io.BytesIO(requests.get(url).content)
pdf = pdfplumber.open(content)
json_string = json.dumps(pdf.metadata, indent=4)
print(json_string)
EOF
python3 /tmp/bitcoin_paper.pyExact output:
{
"Creator": "Writer",
"Producer": "OpenOffice.org 2.4",
"CreationDate": "D:20090324113315-06'00'"
}The PDF document represents a true flag to capture from the perspective of a forensics examiner. As detailed in How you will not uncover Satoshi, the file contains a unique ID that’s essentially an MD5 digest of some known and unknown metadata components in the document. One of the unknowns represented by that MD5 digest is the original document path, which could potentially contain an OS username, and thus a significant clue to the Nakamoto persona’s true identity.
Regardless of the correct and complete document authoring workflow, there is no doubt about some facts around the creation of this PDF file:
OpenOffice.org Writer version 2.4 generated the PDF file. While this software was likely also used to export the content to a PDF file, there is still a possibility that the author didn’t write the paper in this software, and that this software just served as an intermediary to convert the file from another format (for example, a LaTeX file authored elsewhere) into PDF.
Nakamoto used a Windows XP PC
The original PDF contains an ID string that OpenOffice.org generates from an MD5 digest of document metadata items. Some of these items are known, and some are unknown.
One can’t reverse the digest to reveal the values behind the digest, but one could create similar digests from the known items with guesses for the unknowns, and compare to different replacement values for the unknowns to confirm an OS username value as part of the document original filesystem path.
| Known values | Unknown values |
|---|---|
| Title | Author |
| Creator | Subject |
| Producer | Keywords |
| Document creation date |
It’s plausible that the person who authored the paper did so entirely on a Windows XP system using the OpenOffice.org Writer software:
If the person who authored the paper was an academic, then there exists a strong potential authoring workflow that involves TeX/LaTeX due to their popularity in academia:
The following is an abbreviated snippet of code from OpenOffice version 2.4 that shows precisely how it generates the document ID value.
OStringBuffer aID( 1024 );
if( m_aDocInfo.Title.Len() )
appendUnicodeTextString( m_aDocInfo.Title, aID );
if( m_aDocInfo.Author.Len() )
appendUnicodeTextString( m_aDocInfo.Author, aID );
if( m_aDocInfo.Subject.Len() )
appendUnicodeTextString( m_aDocInfo.Subject, aID );
if( m_aDocInfo.Keywords.Len() )
appendUnicodeTextString( m_aDocInfo.Keywords, aID );
if( m_aDocInfo.Creator.Len() )
appendUnicodeTextString( m_aDocInfo.Creator, aID );
if( m_aDocInfo.Producer.Len() )
appendUnicodeTextString( m_aDocInfo.Producer, aID );
...
aID.append( m_aCreationDateString.getStr(), m_aCreationDateString.getLength() );
aInfoValuesOut = aID.makeStringAndClear();
osl_getSystemTime( &aGMT );
rtlDigestError nError = rtl_digest_updateMD5( m_aDigest, &aGMT, sizeof( aGMT ) );
if( nError == rtl_Digest_E_None )
nError = rtl_digest_updateMD5( m_aDigest, m_aContext.URL.getStr(), m_aContext.URL.getLength()*sizeof(sal_Unicode) ); // unicode value
if( nError == rtl_Digest_E_None )
nError = rtl_digest_updateMD5( m_aDigest, aInfoValuesOut.getStr(), aInfoValuesOut.getLength() );
╭───────────────────────────────────────────────────────────────────────╮
│ ⚠ THIS CONTENT MAKES NO CLAIMS ABOUT THE IDENTITY OF SATOSHI NAKAMOTO │
╰───────────────────────────────────────────────────────────────────────╯